
TLDR
- OpenAI’s latest family of models – OpenAI o1 – can mimic human reasoning by thinking through several possible answers before answering a prompt.
- It reasons using a chain-of-thought process, learning through a large-scale reinforcement learning approach.
- A preview, called OpenAI o1-preview, and a smaller model, the o1-mini, are available now to ChatGPT Plus and Team subscribers, with Enterprise and academic users getting access this week.
OpenAI recently unveiled its latest family of AI models that can ‘think’ and ‘reason’ before responding – a “new level of AI capability” that it described as a “significant advancement.” But how good is it?
Called OpenAI o1, these new AI models can chew over their initial responses to your prompt and discard ones they deem incorrect before giving you what they believe is the best and final answer. This process enables the models to tackle tougher problems that need time for thought, such as those in science, coding and math.
For example, health care researchers can use them to annotate cell sequencing data. Developers can use them to build multistep workflows. Physicists can use them to generate complex math formulas for quantum optics, among other use cases.
The preview version, OpenAI o1-preview, was immediately available for paying ChatGPT Plus and Team users, with Enterprise and academic users getting access starting this week. OpenAI also released a smaller, faster and 80% cheaper reasoning model called OpenAI o1-mini for developers. Initially, there will be a weekly limit of 30 messages per week for o1-preview and 50 for the mini.
OpenAI o1 correctly solved 83% of the problems in a qualifying exam for the International Mathematics Olympiad, compared to 13% for GPT-4o, OpenAI’s most powerful large multimodal, general purpose model. The new model ranked in the 89th percentile on competitive programming questions and beat human Ph.D.-level accuracy in physics, biology, and chemistry questions on the GPQA benchmark.
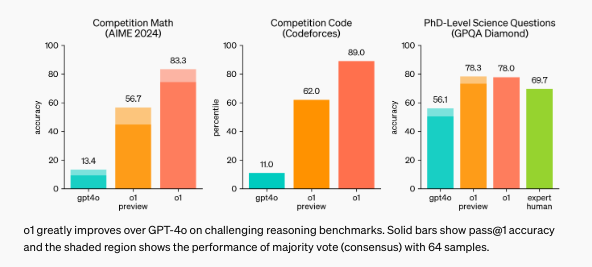
However, it is not as general purpose as GPT-4o, part of OpenAI’s family of GPT models that it plans to continue developing. In the future, o1-preview will get browsing, file and image uploading capabilities.
Putting o1-preview to the test
Ethan Mollick, a Wharton management professor and co-director of the school’s Generative AI Labs, tested the o1-preview (nicknamed ‘Strawberry’ by OpenAI internally). He asked it to solve a particularly hard crossword puzzle, which entails trying different answers and discarding the wrong ones.
“Crossword puzzles are especially hard for LLMs because they require iterative solving: trying and rejecting many answers that all affect each other,” he wrote in his Substack, ‘One Useful Thing.’ “This is something LLMs can’t do, since they can only add a token/word at a time to their answer.”
He took eight clues from the crossword and wrote them out for Claude, Anthropic’s text-only LLM, to solve. It guessed the answer for 1-down was “Star,” which was wrong, and tried to find answers to the rest based on that bad answer, “ultimately failing to come even close,” Mollick wrote.

Giving the same task to o1-preview, the model took 108 seconds to ‘think’ but also got the answer to 1-down wrong: COMA. However, it got creative on the rest: 1-across is CONS, 12-across is OUCH and 15-across is MUSICIANS, for example. What tripped o1-preview was the clue for 1-down: Galaxy cluster. Mollick figured out this meant the smartphone, not the celestial body. The answer to 1-down is APPS.
Giving o1-preview this additional clue, the model solved the puzzle. However, it did hallucinate a new clue, 23-across, which was not in the puzzle clues given by Mollick.
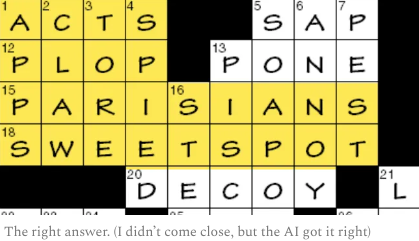
Mollick concludes that o1-preview represents a “paradigm change in AI. Planning is a form of agency, where the AI arrives at conclusions about how to solve a problem on its own, without our help.”
How o1-preview works
OpenAI used a large-scale reinforcement learning algorithm – in which the right answers are rewarded – to teach the model how to think via a chain-of-thought process. The more reinforcement learning it receives and the more time it spends thinking, the better its performance. OpenAI said the limits on scaling this approach “differ substantially” from pretraining of its LLMs, without further explanation.
The chain-of-thought process is similar to a human taking a long time to answer a difficult question as they mull through the possible answers. Using reinforcement learning, the reasoning model learns to see and correct mistakes, breaking down complex steps into simpler ones. It pivots to a new approach if the one it’s using isn’t working.
“This process dramatically improves the model’s ability to reason,” according to an OpenAI blog post.
The chain-of-thought process also lets OpenAI see the thought process of the model so it can monitor the model for bad behavior such as, for example, attempting to manipulate the user. OpenAI said this makes its reasoning models safer because they can think about the safety rules in context. For example, it is four times more effective at thwarting jailbreaks – or attempts by users to bypass safety rules – than GPT-4o.
The startup also said it has enhanced its work on safety, bolstered internal governance as well as federal government collaboration. It has granted the U.S. and U.K. AI Safety Institutes early access to a research version of the model.
For now, OpenAI has decided not to release the raw chains of thought to the public. To learn more about how the OpenAI o1 models work, as well as their purpose and limitations, see the model card.









