Key takeaways:
- MIT-dropout founded Scale AI has raised $1 billion in a Series F round, with Amazon and Meta among the new investors.
- The data labeling startup serves nearly all the leading AI models and counts as clients OpenAI, Meta, Microsoft and others.
- Scale also launched expert-rated LLM leaderboards using private data that it said “can’t be gamed.”
Scale AI, a data labeling startup that serves nearly all the leading AI models, has closed a $1 billion Series F financing round for a reported valuation of $13.8 billion with nearly all existing investors participating – plus new ones including Amazon and Meta.
Founded by MIT dropout Alexandr Wang, Scale AI’s latest funding was led by existing investor Accel with participation from Y Combinator, Nat Friedman, Index Ventures, Founders Fund, Coatue, Thrive Capital, Spark Capital, NVIDIA, Tiger Global Management, Greenoaks, and Wellington Management.Â
New investors are Amazon, Meta, AMD Ventures, Qualcomm Ventures, Cisco Investments, Intel Capital, ServiceNow Ventures, DFJ Growth, WCM, and Elad Gil.
“In 2016, I was studying AI at MIT. Even then, it was clear that AI is built from three fundamental pillars: data, compute, and algorithms. I founded Scale to supply the data pillar that advances AI by fueling its entire development lifecycle,” Wang wrote in a blog post.
Since then, Scale AI has grown in scope to supply data to the AI models of OpenAI, Meta, Microsoft and others. Last August, OpenAI named Scale AI as its preferred partner to help clients fine-tune OpenAI models for their own purposes.
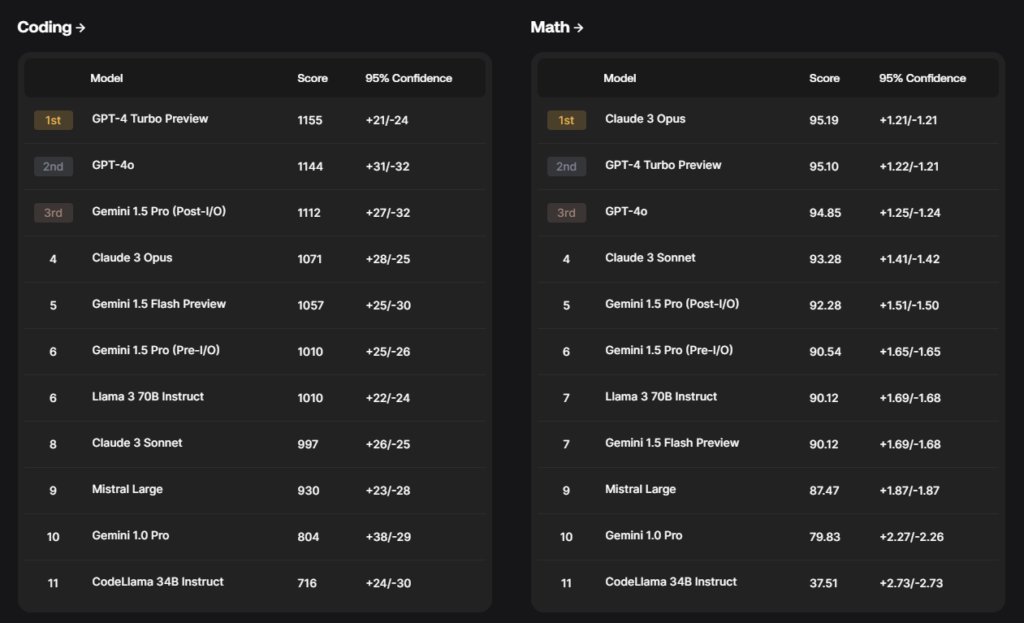
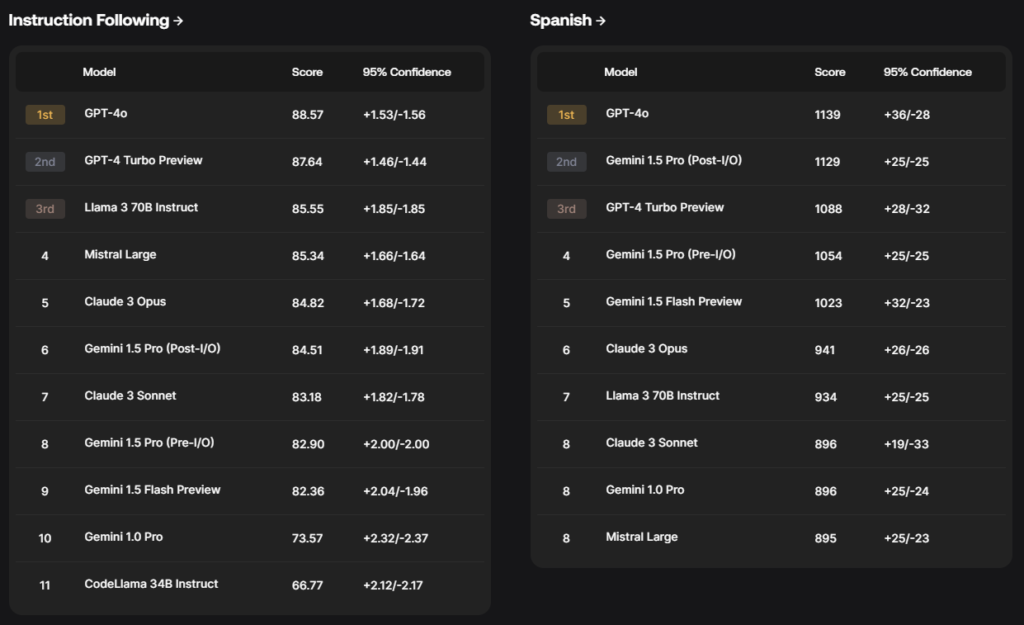
Expert-rated LLM leaderboards
Scale AI also launched its own leaderboards of AI models that use private datasets, which it says “can’t be gamed.” Leaderboards are important because they provide a standardized framework by which to evaluate LLMs, so users can choose the best model for their purposes.
However, the reliability of existing leaderboards faces criticism for being biased (human voting) or the model is trained on the same dataset as the benchmarks, among other maladies. Popular leaderboards are found on Hugging Face, MMLU, Chatbot Arena, MT-Eval and others.
Scale AI hopes to offer more reliable metrics. Its leaderboards use Elo-scale rankings, a mathematical system that ranks participants based on skill levels in games like chess. These are calculated by experts using domain-specific methodologies. Human evaluators compare the responses of two models to the same prompt and rate which one is better along several domains and capabilities.