
Key takeaways:
- Google DeepMind researchers introduced a new technique that creates AI videos with audio for a more cinematic experience. Current video generation models are silent.
- The team let the AI model learn from videos, audio and annotations all together so it can output audiovisual content.
- The researchers said they still have to improve lip synching with mouth movements.
Google DeepMind researchers unveiled a new technique that creates AI videos with audio for a more cinematic experience, an advancement in the field of AI-generated videos.
Current text- or image-to-video generation models can create realistic-looking videos but they are silent. The DeepMind team developed its video-to-audio (V2A) technology to enable an AI model to generate audiovisual content.
“V2A combines video pixels with natural language text prompts to generate rich soundscapes for the on-screen action,” the researchers said in a blog post.
DeepMind said V2A can be used with video generation models like its Veo “to create shots with a dramatic score, realistic sound effects or dialogue that matches the characters and tone of a video.” V2A can also create soundtracks for traditional footage such as archival material and silent films.
Notably, the researchers said V2A can create an “unlimited” number of soundtracks for a video – with a “positive” prompt telling the AI model what sounds it wants more of and a “negative” prompt the sounds it wants less of in the video. This gives users more flexiblity to craft the audio.
How it works
The process starts with encoding and compressing the video, then the diffusion model iteratively refines the audio from random noise. “This process is guided by the visual input and natural language prompts given to generate synchronized, realistic audio that closely aligns with the prompt,” they said. “The audio output is decoded, turned into an audio waveform and combined with the video data.”
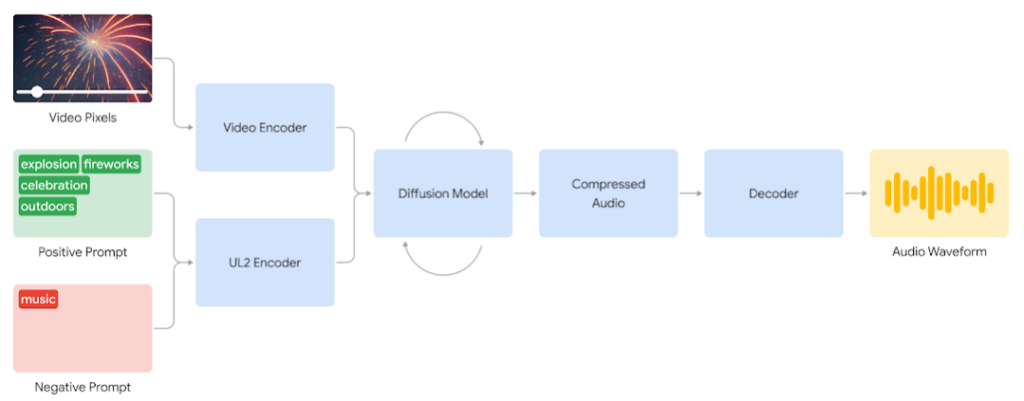
Basically, it takes the video pixel and audio prompt to generate an audio waveform synchronized to the video.
To raise the quality of the audio and teach the model how to generate specific sounds, the researchers added AI-generated annotations, sound descriptions and transcripts of dialogue. By training on video, audio and annotations all together, the model learns to associate certain visuals with sounds as guided by the annotations.
With this system, users don’t have to manually adjust the timing of the audio and video to make them sync. However, the researchers said they still have to work on lip synching since mouth movements may not move in tandem with the generated speech.







