
TLDR
- AI supercomputer startup Cerebras unveiled an inference service it said is much faster and much cheaper than the GPU-based solutions offered by cloud giants.
- The secret is its giant, plate-sized chip that can store an entire language model. In contrast, data on GPUs have to travel to external memory and back for the compute, slowing the process.
- The speed claims are backed by a third party benchmark firm, Artificial Analysis.
One of the main sticking points against faster AI deployment is the cost. Now, an AI supercomputer startup has unveiled an AI inference service that it said is not only much faster, but also a lot cheaper.
Silicon Valley-based Cerebras Systems said its AI inference service is faster than all of its competitors. Inference is the process by which new data is fed into an already trained AI model, to yield new insights or accomplish new tasks. This is the bread-and-butter of the AI compute market; it is the fastest growing part of AI compute and makes up about 40% of the total AI hardware market.
Cerebras said its system is 20 times faster than Nvidia’s GPU-based solutions that are offered by the largest cloud providers. Also, prices start at 10 cents per million tokens. (A million tokens equals roughly 750,000 words.) That is 100 times higher price-to-performance ratio for AI workloads, it claimed.
“We are now the world’s fastest at inference. We are at the most accurate level, and we’re the cheapest,” said Cerebras CEO Andrew Feldman, in a podcast with Weights & Biases.
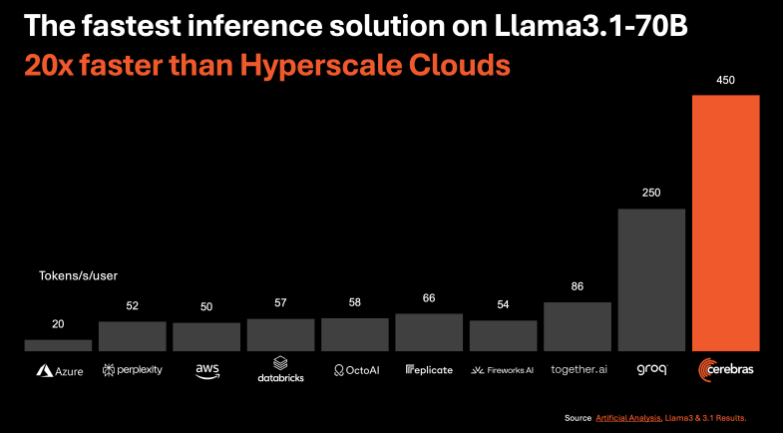
The startup said it delivers 1,800 tokens (roughly 1,350 words) per second for Meta’s Llama 3.1, 8 billion parameter model, and 450 tokens per second for Llama 3.1 70B.
Artificial Analysis, a benchmarking firm, said it has verified these claims. Cerebras has “taken the lead” in AI inference benchmarks and has reached a “new record,” according to Artificial Analysis.
High-speed AI inference at above 1,000 tokens per second is akin to the development of broadband internet, the startup said, implying that today’s speeds could be compared to dial-up internet. Inference speed may also accelerate the development of AI agents – bots that do tasks for people, instead of just telling you what to do – because speed matters when making decisions in real time.
The faster speeds come at a fifth of the price, Cerebras added. Inference on both models costs 10 cents per million tokens for the 8B Llama model, and 60 cents per million tokens for the 70B model.

Cerebras’ secret is its Wafer-Scale Engine 3 chip (WSE-3), the largest in the world at the size of a plate. This chip powers its CS-3 system, which can be clustered together to make AI supercomputers that run the large language models.
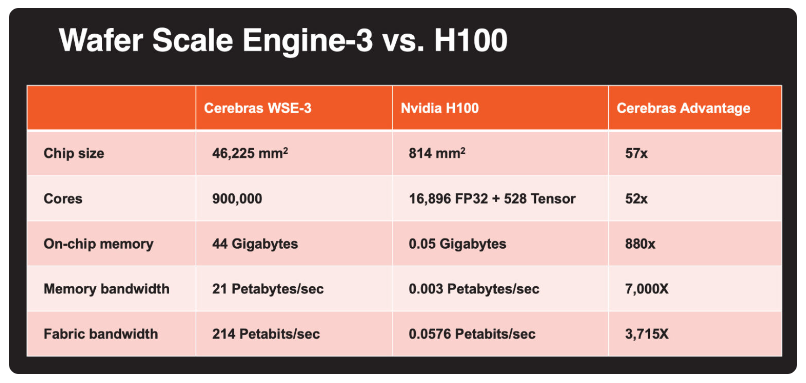
Cerebras said its chip is big enough that it can store an entire model, due to its 44GB of SRAM. In contrast, GPUs don’t have as much memory and thus the data travels to external memory and back – making compute slower. The startup also said WSE-3 has 21 petabytes per second of aggregate memory bandwidth, or 7,000 times that of Nvidia’s H100 AI chip.
Moreover, Cerebras said it uses 16-bit model weights, which leads to better accuracy. It claims that others get over the memory bandwidth problem by using 8-bit weights, but outputs can be less accurate.
Cerebras inference is available via chat and API access, but only for Llama 3.1 8B and 70B models at present. It will be adding support for other models in coming weeks.
