
Key takeaways:
- Today, OpenAI unveiled its smallest and cheapest multimodal model yet: the GPT-4o mini.
- GPT-4o mini is “an order of magnitude more affordable” than its older models and 60% cheaper than GPT-3.5 Turbo, which had been the prevailing best deal.
- The move comes as enterprises grapple with the high cost of adopting generative AI, among other issues.
As astounding as OpenAI’s GPT-4o capabilities have been, a sticking point for enterprise adoption has been the cost, complexity and risks of generative AI.
Today, OpenAI sought to address at least one of those concerns by introducing GPT-4o mini, a smaller and cheaper multimodal model. The mini is available now to free, Plus and Team users of ChatGPT, with enterprise users getting access next week.
GPT-4o mini is “our most cost-efficient small model,” OpenAI said in a blog post. “We expect GPT-4o mini will significantly expand the range of applications built with AI by making intelligence much more affordable.”
The mini is “an order of magnitude” cheaper than its older models and over 60% less expensive than GPT-3.5 Turbo, its prevailing best deal, according to the startup. (This is pricing for developers to incorporate the model into other systems; consumers and small teams pay a flat-fee monthly rate, which will not change.)
OpenAI is charging developers 15 cents per million tokens for input – what users enter into the prompt window – and 60 cents per million tokens for output – what the model generates. (A token consists of word or character groupings. A million tokens translate to roughly 750,000 words or 3,000 pages.)
As a comparison, GPT-3.5 Turbo costs 50 cents per million input tokens and $1.50 per million output tokens. (Batch API prices are 25 cents input and 75 cents output for Turbo.) As for its rivals, Anthropic’s Claude 3 Haiku charges 25 cents per million input tokens and $1.25 per million output tokens.
“We think people will really, really like using the new model,” OpenAI CEO Sam Altman tweeted.
Context window and performance
The mini has a sizable 128,000-token (128K) context window that can take in about 96,000 words for the prompt. However, Google’s Gemini 1.5 Pro – a large model – blows away everyone in the industry with a context window that can handle up to 2 million tokens. For output, the mini offers up to 16K tokens per request.
The mini offers text and vision capabilities in the Assistants API, Chat Completions API, and Batch API, with image, audio and video coming later. Its knowledge cutoff is as of October 2023.
In performance, the mini scored 82% on the MMLU (Massive Multitask Language Understanding) benchmark, which measures proficiency in a range of tasks and domains like science, humanities and math. This compares with 77.9% for Gemini Flash and 73.8% for Claude Haiku, both rival small models.
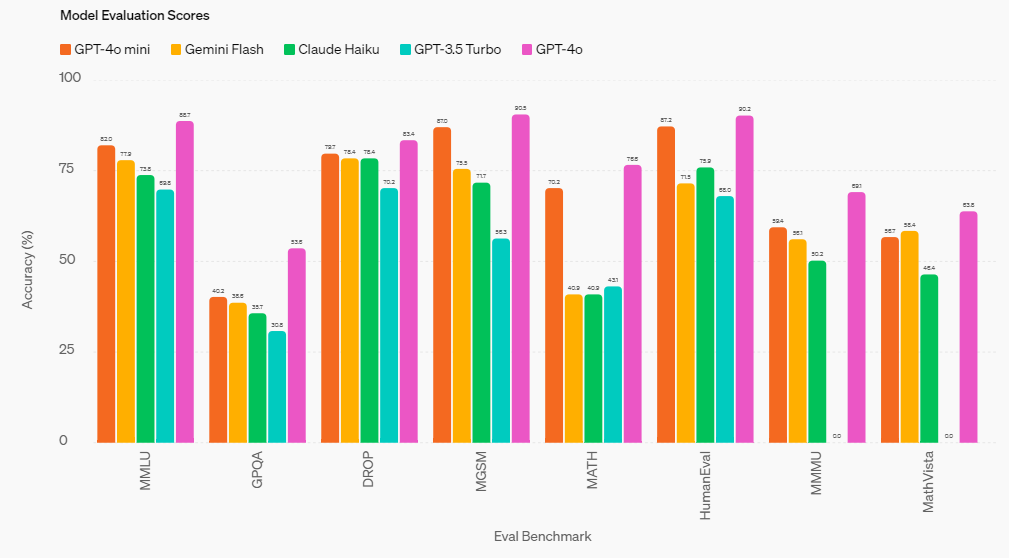
OpenAI said the mini overall outperforms its own GPT-3.5 Turbo and other small models on academic benchmarks in “textual intelligence and multimodal reasoning.” It supports dozens of languages, just like GPT-4o. The mini is “strong” in function calling and has better long-context performance than the GPT-3.5 Turbo, the startup said.
The mini is also the first model to apply OpenAI’s “instruction hierarchy method,” which makes it more resistant to misuse in jailbreaks, prompt injections and system prompt extractions.
OpenAI will be rolling out fine-tuning capabilities for the mini in the “coming days.”
Smaller language and multimodal models are becoming more popular because they are easier to fine-tune or retrain for specific uses, require less computational power, process AI workloads faster with lower latency, have faster deployment, consume less energy, and are sized to better fit mobile devices like laptops and smartphones for edge computing.
Mistral and Nvidia today released a small, 12-billion parameter model called Mistral NeMo. It is open source and boasts a 128K context length window. The model is meant for multilingual tasks, particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic and Hindi. It uses a new tokenizer that was trained on more than 100 languages.
Microsoft has introduced its small model Phi-3 family; Google has its Gemma models; Anthropic has Claude 3 Haiku; Mistral AI has Mistral 7B; Meta has Alpaca 7B, among others.
