TLDR
- Google DeepMind unveiled Genie 2, an updated version of its AI model that can turn a single image and text description into a video game.
- Genie 2 creates playable 3D environments for humans and AI bots. Genie 1 was only in 2D.
- Google DeepMind said Genie 2 could be used to train AI-powered robots in simulations, which would be safer than doing so in the physical world.
Google DeepMind, the search giant’s AI division whose CEO just won a Nobel Prize, has unveiled an updated version of its AI model that can turn a single image and text description into a video game.
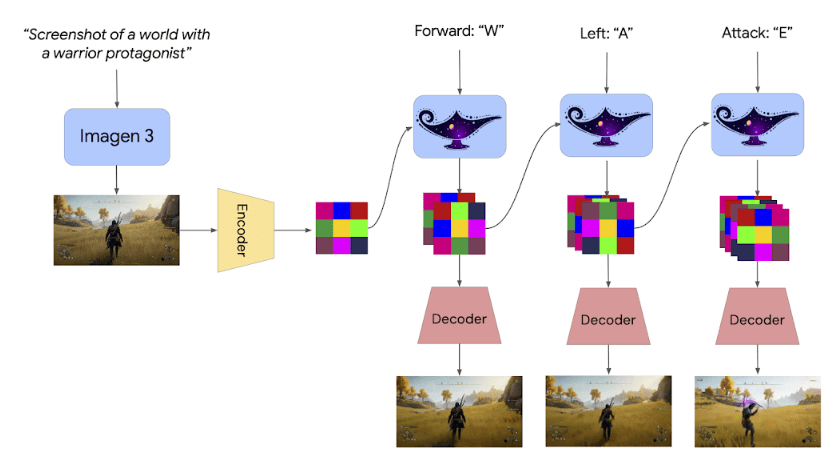
Called Genie 2, the foundation world model can create a variety of “action-controllable, playable 3D environments” for humans or AI agents using a keyboard and mouse. Genie 1 was limited to 2D.
Genie 2 is called a world model because it can simulate virtual worlds. Trained on a large-scale video dataset, Genie 2 can display object interactions, complex character animation, physics (such as gravity and splashing water effects) and behavior modeling of other agents. The world it creates can last up to a minute, with most in the 10- to 20-second range.
“This means anyone can describe a world they want in text, select their favorite rendering of that idea, and then step into and interact with that newly created world,” wrote Google DeepMind researchers in a blog post.
The games can be used to train generalist AI robots in different environments. A common problem is the lack of rich, diverse and safe training environments for so-called embodied AI, the researchers said.
How it works
Genie 2 is a powerful AI model that learns from a large video dataset and uses a process that compresses video frames into simpler, meaningful representations through an autoencoder. These compressed frames are then analyzed by a transformer model that predicts how the video should progress, step-by-step, using a method similar to how text-generating models like ChatGPT work.
When Genie 2 is creating new videos, it generates them one frame at a time, using previous frames and actions as a guide. To make sure the actions in the video are more controlled and realistic, it uses a technique called classifier-free guidance.