
TLDR:
- Foundation model advancements soar while enterprise implementation is not keeping pace.
- Two big blockers to deploying AI: challenges in customizing models to fit specific business needs and lack of adequate benchmarks to effectively evaluate models.
- 65% of organizations choose out-of-the-box AI models but said these do not meet their needs. Also, lacking adequate benchmarks, 56% tap industry standards by following leaderboards for public benchmarks.
Every few months brings another advancement in foundation models whether it comes from OpenAI, Google, Meta or AI startups. But the pace of enterprise adoption, deployment and scaling of AI is another story: It is not keeping up and could even be slowing.
A recent survey from Scale AI – whose report weeds out responses from business folks not directly involved with AI – dug deeply into the reasons for this gap: Companies face challenges in customizing models for their needs; there also is a lack of appropriate benchmarks to effectively evaluate them.
While most use out-of-the-box generative AI solutions, these often do not meet companies’ specific needs, the survey said. To complicate matters, insufficient benchmarks mean that measuring the return on investment is not easy. As such, it is no wonder companies are treading more cautiously into AI despite the astounding advances seen in foundation models.
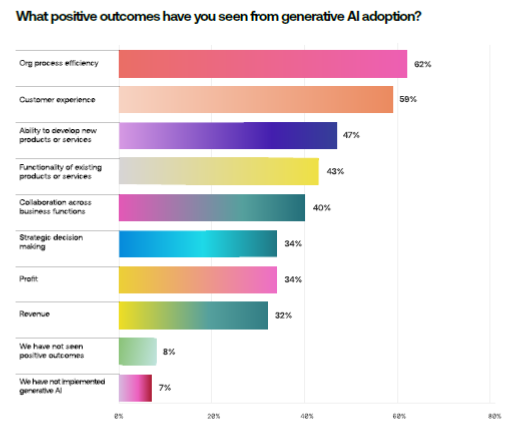
For example, 79% said their number one reason for adopting AI is to increase operational efficiency. But only half of the respondents are measuring the business impact of their AI initiatives in areas such as revenue, profits and strategic decision-making.
Respondents want to evaluate models for performance (69%), reliability (69%) and safety (55%).
All told, 40% of the 1,800 ML practitioners surveyed said their organizations are implementing and deploying AI models. The remaining 60% that are not doing so cited security concerns, lack of expertise and other initiatives taking priority as the top three reasons for their hesitation. (The survey was conducted online in the U.S. from Feb. 20 to March 29.)
‘Prompt templates’ and RAG issues
Looking at generative AI implementation specifically – generative AI is a subset of AI/ML − the survey showed that 38% of respondents have models in production while 62% either experimented with it, are planning to do it or have no plans at all.
The top three uses for generative AI are computer programming, content generation and data analysis.
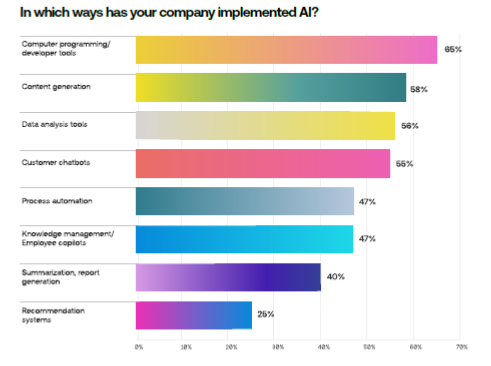
In coding, “copilots†– in which the AI model writes or fixes code to accelerate the software development process − are becoming mainstream with users quickly taking to solutions such as GitHub Copilot, CodeLlama and Devin, according to the survey.
In content generation, AI model vendors give clients “prompt templates†to guide them in marketing, product management and public relations tasks.
But hurdles to deployment remain: infrastructure issues, inadequate tooling for tasks such as data preparation, model training and deployment (61%), insufficient budget (54%), data and privacy concerns (52%) and others.
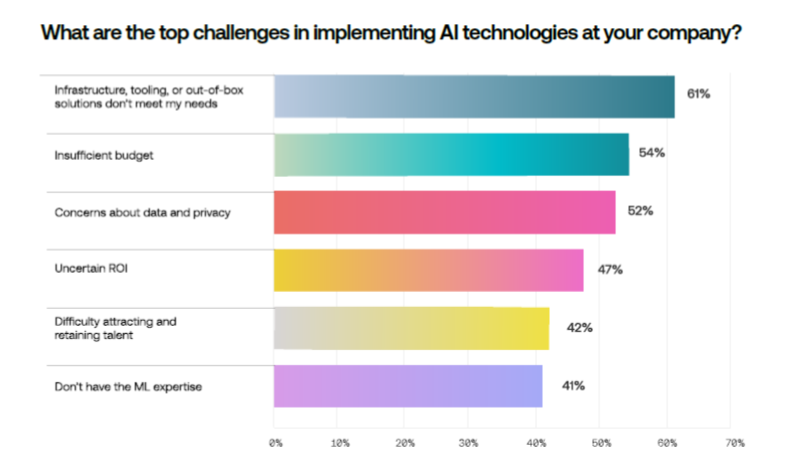
When they buy generative AI solutions, organizations prefer OpenAI by far, with 58% using GPT-4 and 44% using GPT-3.5. Google’s Gemini comes in third at 39%. Other models see significantly lower patronage.
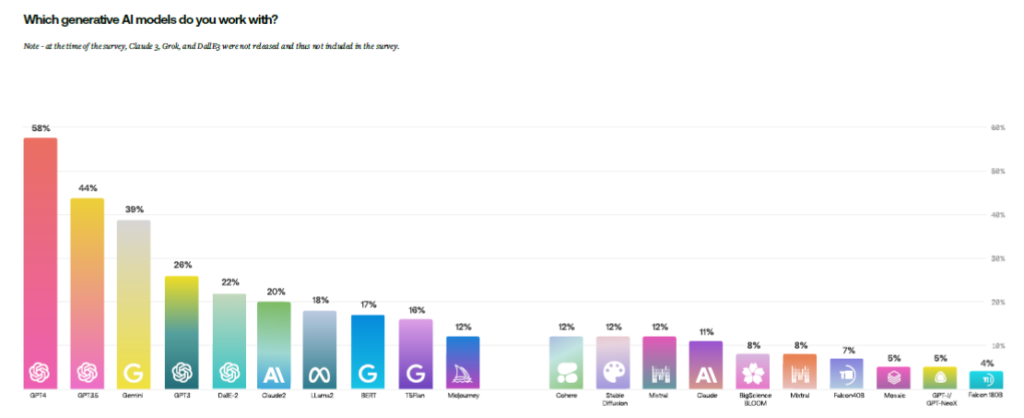
The majority (65%) of respondents buy closed or proprietary generative AI models out of the box, but these still often do not meet the needs of their specific businesses. The majority (65%) of respondents buy closed or proprietary generative AI models out of the box, but these still often do not meet the needs of their specific businesses.
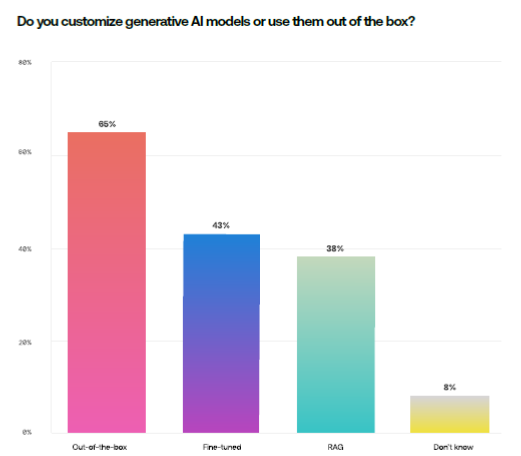
To customize the models, organizations typically use prompt engineering – giving the model very specific instructions to customize output – fine-tuning and Retrieval Augmented Generation (RAG) techniques.
Fine-tuning refers to retraining the models on specific tasks or datasets to boost performance and accuracy. RAG takes it a step further by adding external information to the generation process.
But respondents said fine-tuning and RAG brings in the added complexity of integrating external data sources in real time, ensuring relevance and accuracy of the output, managing additional computational costs and addressing biases and errors.
Fine-tuning also must be carefully done to avoid overfitting – becoming too specialized – so that the model still can be generally applied to new data.
MacGyver-ing Gen AI benchmarks
Survey respondents said the big blocker in fine-turning is evaluating performance (32%) and data transformation (31%). As for RAG, 28% say the top challenge is evaluating performance.
RAG helps large language models get a factual understanding of the world so they can better explain the reasoning behind their outputs. It does this by connecting the model with known data sources such as a bank’s general ledger, according to Jon Barker, a Google customer engineer who was quoted in the survey.
However, RAG “requires creating and maintaining the external data connection, setting up a fast vector database, and designing vector representation of the data for efficient search,†he said.
But “keeping this vectorized representation of truth up-to-date is tricky. As the underlying data sources change over time and users ask new questions, the vector database needs to evolve as well. … The industry is still grappling with how to design RAG systems that can continually improve over time.â€
The other key issue is that current model evaluation benchmarks are not robust enough to reflect how they will perform in the real world. “Traditional academic benchmarks are generally not representative of production scenarios, and models have been overfitted to these existing benchmarks due to their presence in the public domain,†the report said.
As such, “leading organizations are moving towards comprehensive private test suites that probe model behavior across diverse domains and capabilities.†However, “universally agreed upon third-party benchmarks are crucial for objectively evaluating and comparing the performance of large language models†that are standardized and transparent, Barker said.
Indeed, 56% of companies tap industry safety and reliability standards by following leaderboards for public benchmarks, the survey found.
Generative AI deployment to grow
While companies and AI foundation model builders work towards solutions, survey respondents nevertheless remain bullish about generative AI.
Nearly three-quarters of respondents said their organizations see AI as “very or highly critical†to their business in the next three years (up from 69%) and 72% plan to increase their investment in this area in the same timeframe (flat from prior year).
Nearly 40% said they have generative AI models in production, up from 21% last year. Almost 20% said generative AI forced them to come up with an AI strategy, up from 12% last year. Only 4% of respondents said they have no plans to work with generative AI, down from 19% in 2023.
“The rapid evolution of AI offers both immense opportunities and challenges,†said Alexandr Wang, founder and CEO of Scale who was reportedly once considered as a replacement for OpenAI CEO Sam Altman, in the report. “Embracing it responsibly, with robust infrastructure and rigorous evoluation protocols, unlocks the potential of AI while safeguarding against the risks, known and unknown.â€